
AI Sketch Artist: Can it really learn any style?
Fine-tuning my dads caricature style

With the obvious application of GenAI to reproduce a famous artists style - I wondered, if it can do the same for a local artist master like my dad. Although his art dataset is somehow available on the public Internet - it isn’t labelled well for the general model to reproduce it.
Plan - or not
Having a true Unsupervised Journey spirit, I have developed this bullet proof plan:
Try: Lets just do something, I heard OpenJourney works ok.
Feedback: See how it looks
Iterate: Start over with the extended knowledge
Step 1: Lets just try something
Google: “Use OpenJourney”, click on first non-advertisment link and try some prompts like
“lionel messi”
“a caricature drawing of lionel messi”
IF I would continue for two more hours, I could get the third picture. But I didn’t.

TLDR - it was somewhat promising - but I wanted to get closer to my fathers mastery:

The difference to the generated pictures is obvious. For example you can see there are many intricacies to be perfected, especially:
a more nuanced skin,
a stroke-detailed hair and
some funny object for the character (this is Ivan Miklos, a former finance minister of Slovakia).
Step 1: Take the idea of custom avatars
Back in spring, everyone was hyped about their AI-generated avatars. It is pretty cool - you upload 10-20 pictures of yourself and you could generate (almost) whatever pose you wanted. For example you being on a moon riding an unicorn or your next LinkedIn headshot.

How this works under the hood? It’s essentially like teaching an adult artist on new knowledge. You repeatedly show the model new pictures of the new object (the person), and then you ask the model to draw it. On the neural network layer it essentially further trains the general model with a lower learning rate. This process is called fine-tuning, and that new knowledge can also be a new style.
Training the style
So now I have three problems:
Get the training data to teach the knowledge of dads mastery
Fine-tune OpenJourney
Generate outputs (and iterate on the above).
For the first, it was kinda easy cause my dad gave a deck of cards in an uniform style of famous people in czechoslovakia. So I just went ahead, snapped pictures on my smartphone and voila!
For the other two, luckily there are quite a few services doing model fine tuning for me. So I have tried LeapAI, LeonardoAI and RunwayAI - and after early results I have decided to commit to LeapAI.
The process was roughly:
Hit Create New Model
Upload your sample images - 20 is enough
Wait for model finishing fine-tuning - that took about 30mins.
Go to Playground and enter your prompt.
PRO TIP: Here, you should pick a well-known well-defined recent subject. Cause I first picked Albert Einstein first (who has no high-quality photo) and then Cristiano Ronaldo (and there are many very famous Ronaldo’s).

Conclusion from the prototype
I was pumped that it looked pretty good for the first pass so I shared it with my brother and he said “wow”.
But it was still far from the desire, and first the first Iteration I had a few ideas to improve:
Input images
Use the good old scanner instead of my camera for consistent image quality
Crop pictures to 512x512, with faces only with cropped out backgrounds
Used 50 images instead of 20
Prompt engineering
I have used ChatGPT to iterate on prompts. This ended up being more of a black magic than a scientific process as I ended up trying almost 100.
Inference parameters experimentation:
Steps: (more seemed to work better)
Temperature / Prompt strength (more variance in output)
#Images (more output, higher chances of success :D)
Next Iteration: Consistent Data
My intent was to train portrait drawings, so I focused the input data to do that. These images were:
scanned at the same resolution, placement and cropping style (previously just camera pics).
manually post-processed (removed background, unnecessary parts, …)
scaled to 512x512 pixels which is the same resolution as the base models are trained on

Lets now compare how much the underlying data helped to achieve our goals. We are using the same prompt “a photo of lionel messi” with the difference of our fine-tuned model - this was a STEP CHANGE. I got pumped.

Next Iteration: Better prompts
Now, I best-effort tried to describe what I want to achieve. Most of the work was finding the right words for “caricature” (was “a caricature drawing of”) and my dads style (was “crosshatching”). The final prompts:
Positive: a caricature drawing of {person},
headshot, profile, slightly smiling, lines, intricate hair,
fits in frame, crosshatching, textured, fine strokes
Negative: duplicate, malformed, color, mutated, jpeg artifacts,
out of frame, digital, smooth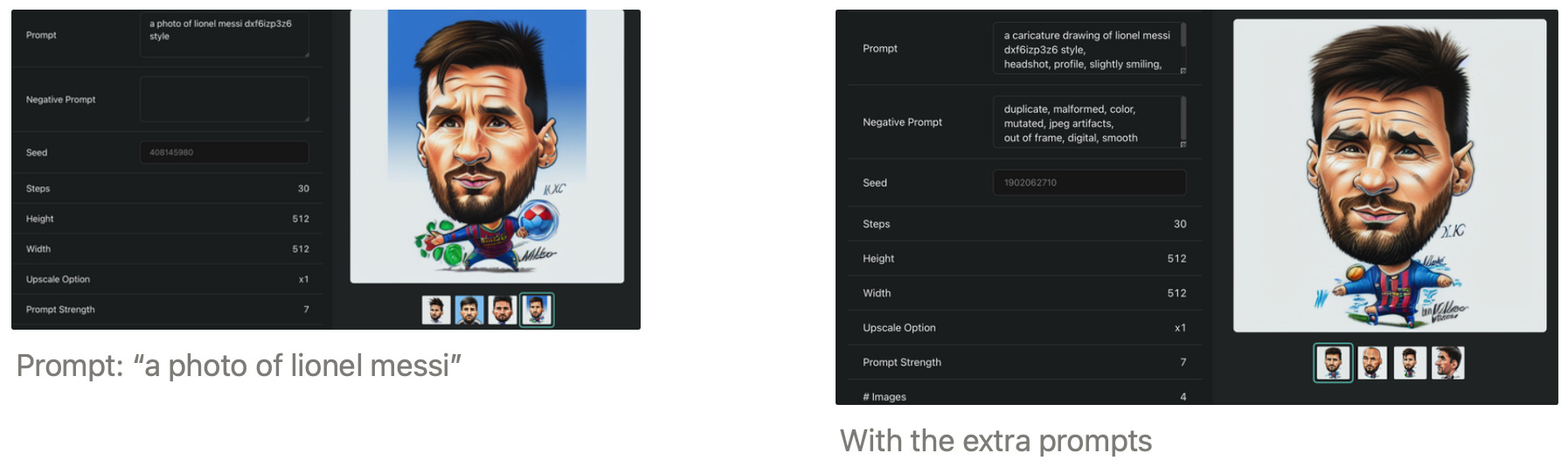
Next Iteration: Parameter Tuning
TLDR; I just pretty much tried all parameter combination using a “binary search” process:
High-level best params
Prompt strength (temperature): 4, 7, 10, 13, 16
Steps: 20, 30, 50, 70, 100 (NOTE: more steps takes longer)
Narrow it down for the best combo - say it’s 10 strength and 70 steps then I would try:
8, 9, 10, 11, 12 strengt
60, 65, 70, 75, 80 steps
PRO TIP: Set the Seed parameter during experimentation to get deterministic and more comparable results. Also use as many output images as possible.

Oh, and wait what did my dad say? 🤪
Well, how should I tell my dad that machines are after his job which he is super-proud of?
So I ended up ordering him a canvas print of the 32 soccer captains from last FIFA world cup and patiently waited for his call 😀

TLDR on response: Denial.
So after text and images, I went onto exploring voice AI.